Réseau de neurones

Introduction aux réseaux de neurones.
L'intelligence artificielle comporte une multitude de domaines, dont l'apprentissage machine (machine learning).
L'une des techniques de ce domaine est l'apprentissage profond (deep learning), et celle-ci utilise des réseaux neuronaux pour certains types d'apprentissages.
Neurone
Au départ, les chercheurs en informatique se sont inspirés du cerveau humain pour tenter de reproduire son fonctionnement artificiellement.
En 1943, McCulloch et Pitts ont établis les bases des premiers neurones artificiels.
Biologie
En simplifiant énormément, un neurone biologique comporte trois éléments principaux :
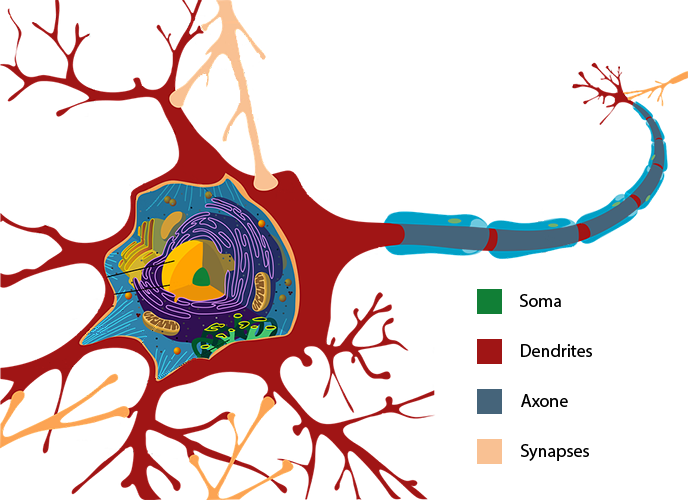
Le somma (noyau) reçoit des impulsions électriques de ses dendrites (entrées). Selon l'intensité des impulsions reçues, le somma transmet, ou pas, une impulsion électrique par son axone (sortie). Les synapses, quant à elles, permettent de lier les axones aux dendrites afin de former un réseau.
Programmation
On peut aussi visualiser un neurone comme étant une fonction (soma), qui reçoit des paramètres (dendrites), et retourne un résultat (axone).
Réseau
En 1958, Frank Rosenblatt lie des neurones de façon à crée le plus ancien, et le plus simple, des réseaux neuronaux: le perceptron.
Rosenblatt va un peu plus loin que McCulloch et Pitt, en ajoutant une notion de poids aux calculs.
Perceptron
Un réseau neuronal de type perceptron contient (S) neurones, chacunes liées à (D) entrées, et produit (A) sorties. De plus, les synapses reliant les neurones possèdent maintenant un poids :
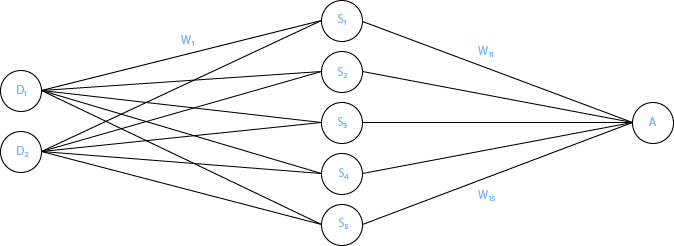
Couches
On nomme « couche cachée » les neurones entre les entrées et les sorties. Si le réseau perceptron est simpliste, il permet aussi de résoudre que des problèmes relativement simples. Pour résoudre des problèmes plus complexes, plusieurs couches cachées peuvent être ajoutées :

Propagation
On nomme « propagation avant (feedforward) » les calculs qui sont effectués entre les couches cachées.
Toute l'information se dirige dans le même sens: des noeuds d'entrés, par les noeuds cachés, jusqu'aux noeuds de sorties.
Calculs
Chaque neurone fera une somme pondérée des poids des synapses avec les données d’entrée afin d'estimer un rendement :
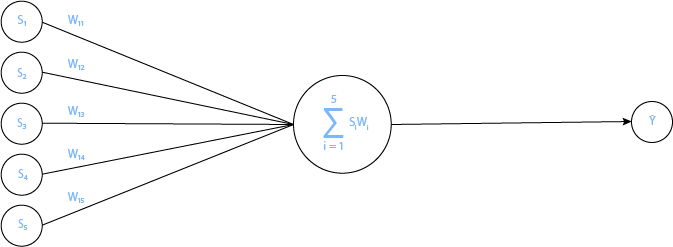
Activation
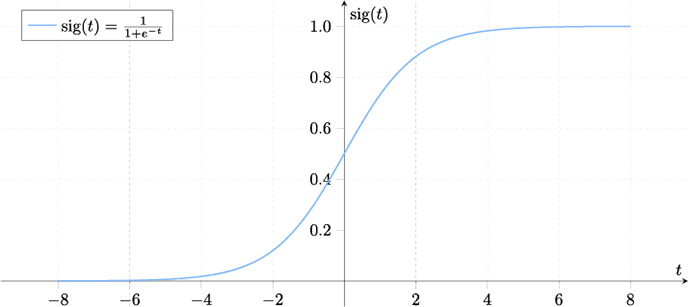
Pour déterminer l'activation de chacun des neurones, il existe une multitude de fonctions telles Linéaire, Seuil, Sigmoïde, ReLU, etc., ayant chacune leurs spécificités :
Rétropropagation
En 1974, Paul Werbos est l'un des premiers à observer l'application de la rétropropagation (backpropagation) au sein des réseaux neuronaux.
C'est cette technique qui permettra au réseau neuronal de s'ajuster, en apprenant de ses erreurs.
Coût
On nomme « coût » la gravité de l'erreur commise. Ce coût est calculé à partir du résultat obtenu versus le résultat attendu.
Tout comme la fonction d'activation, il existe une multitude de fonctions de coûts selon les besoins.
Ajustement
Le coût permettra de calculer les ajustements, que l'on nomme « gradient », à apporter au poids de chaque synapse.
Exemple
Exemple simpliste d'un réseau neuronal, de type perceptron, afin d'apprendre un opérateur logique :
import numpy as np
def sigmoid(x):
return (1 / (1 + np.exp(-x)))
# Réseau de neurones
neuronesA = np.vstack(([0, 0], [0, 1], [1, 0], [1, 1]))
synapsesA = np.random.rand(2, 16)
neuronesB = []
synapsesB = np.random.rand(16, 1)
neuronesC = []
# Résultats attendus pour l'opérateur logique ET
resultats = np.vstack(([0], [0], [0], [1]))
# Apprentissage
for i in range(1000000):
# Propagation avant
neuronesB = sigmoid(np.dot(neuronesA, synapsesA))
neuronesC = sigmoid(np.dot(neuronesB, synapsesB))
# Gravité des erreurs
graviteErreurs = (neuronesC - resultats) * neuronesC * (1 - neuronesC)
# Propagation arrière
gradiantB = 2 * np.dot(neuronesC.T, graviteErreurs)
gradiantA = 2 * np.dot(neuronesA.T, np.dot(graviteErreurs, synapsesB.T) * neuronesB * (1 - neuronesB))
# Ajustement des poids
synapsesB = synapsesB - gradiantB
synapsesA = synapsesA - gradiantA
# Prédictions
for i in range(4):
print(neuronesA[i], round(neuronesC[i][0], 0))